


HOME

De enteres
Chiò te troes la piates de enteres





Ressorses online
Link a la ressorses online
Chiò te troes i link a la ressorses.




Majon di Fascegn

- Prejentazion
- Informazions e oraries
- Attività editoriale
- Servijes linguistics
- Dizionères e ressorses linguistiches
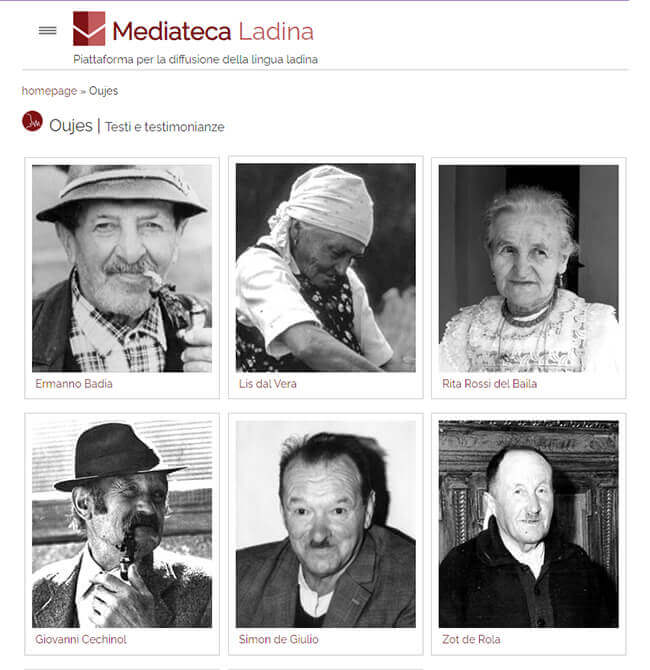
- Mediateca Ladina
- Prejentazion
- Informazions e oraries
- Servijes de la biblioteca
- Biblioteca online
- Archivies
- Prejentazion
- Informazions e Oraries
- Museo sul teritorie
- Patrimonie etnografich
- Servijes Educatives
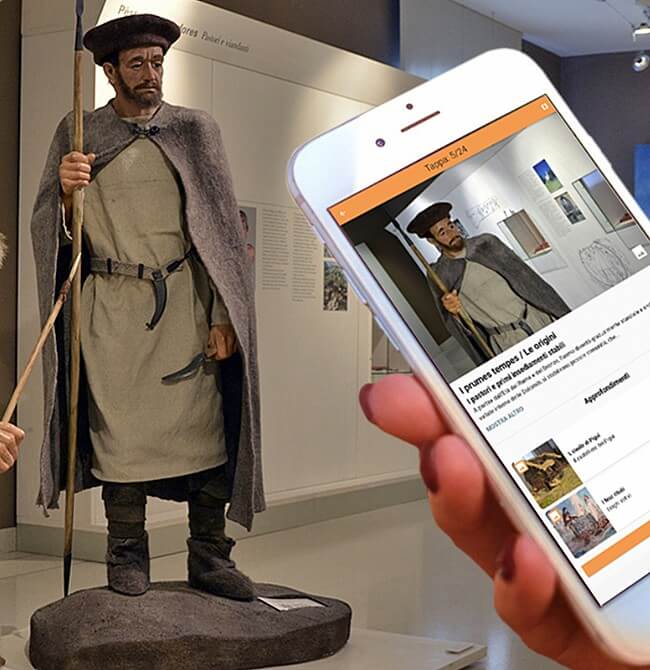
- Tour Virtuèl
- Pigui Experience
- Mobicult
 Istitut Cultural ladin
Istitut Cultural ladin
- Prejentazion
- Informazions e oraries
- Attività editoriale
- Servijes linguistics
- Dizionères e ressorses linguistiches
- Mediateca Ladina
 Biblioteca Ladina
Biblioteca Ladina
- Prejentazion
- Informazions e oraries
- Servijes de la biblioteca
- Biblioteca online
- Archivies
 Museo Ladin de Fascia
Museo Ladin de Fascia
- Prejentazion
- Informazions e Oraries
- Museo sul teritorie
- Patrimonie etnografich
- Servijes Educatives
- Tour Virtuèl
- Pigui Experience
- Mobicult